
Big Data and advances in Artificial Technology have outstripped current processor technology. Compute Accelerators and GPUs have filled the gap providing thousands of compute cores, field programmable gate arrays, specialised AI-specific cores and high bandwidth interconnection.
Most systems are configured with dual processors, a lot of RAM (starts at 256GB but much more is common), high speed SAS SSDs or NVMe, multiple high wattage power supplies and multiple compute accelerators or GPUs.
A specialised bus is also quite common at the high-end allowing faster interconnect between GPUs.
What Makes a High-Performance Compute server
Different?

High Performance Compute servers generally use
the highest performance processors available. These generally have a high clock
rate and a large number of cores.
AMD
currently have the performance edge with up to 64 cores at 3.4GHZ. They also
offer a range of 32 core processors.
Intel
has the 28 core 8280 at 2.7ghz shipping and announced 56 core processors having
discontinued its Phi 64-72 core processors.
HPC
Processors are low volume and very expensive items with each processor costing
tens of thousands.
We have
selected the fastest and latest processors in our high-end systems and offer
slightly slower processors in our mid-range systems.
 |  | We have a number of our HPC Servers offering Dual AMD 64 core. We also offer multiple Intel 28 core processors in a number of our systems |

Most of the high-performance servers run
DDR4-2999GHZ RAM although faster RAM is available it is often not supported by
the Equipment manufacturers.
Most
high-performance Compute servers have a minimum of 512GB RAM although systems
with 3TB or more are available.
There is
also use of Intel Optane DC Persistent RAM available in 512GB modules to
massively expand the maximum memory size and provide non-volatile storage for
in-RAM databases.
We
have the complete Intel Optane Range available and able to be included in many
of our HPC Compute configurations.


The industry standard PCIE3 bus is currently
being updated to PCIE4 effectively doubling the transfer rate from 32GB/sec to
64GB/sec.
For
systems with a large number of GPUs Nvidia has SXM3/NVLINK bypassing the PCIe
bus and providing up to 300GB/sec between GPUs.
 |  | We have the largest range of SXM3 systems available in Australia and new PCIE4-based systems |

The HPSS Collaboration is an organisation specifically addressing High Performance Computing storage requirements.
PetaFlops understands storage performance is critical and so SAS SSD technology is preferred. Many systems are also utilising M2.NVMe for its advantages in transfer rates.
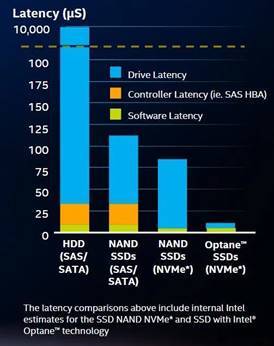
As you can see from the chart, Intel Optane offer extremely low drive latency and the use of the memory slots avoids significant controller latency.
The use of Intel Optane DC RAM (see above) is perfect for certain HPC operations but M2.NVME and SAS SSDs are more commonly used.
 |  | We offer M2.NVMe in several of our High-Performance Systems. Others have arrays of high performance SAS SSD. |

The Infiniband 200GB/sec is still popular for
multi compute-node supercomputers but 100GB/Sec ethernet products are also
considered.
For
industry applications a minimum of 10GBE ethernet is recommended.
All
Petaflops systems come with a minimum of 10GBE network connections.

Nvidia has recently
upgraded its V100 to V100s and this has been measured at 8.2TFLOP for FP64
double-precision floating point operations.
Its V100 and V100S both have 5120 CUDA compute cores and 640 AI specific Tensor
cores per board. With 8 board systems performance of over 50TFLOPS with
more than 40000 compute cores and 5000 tensor cores are possible. |  |


AMD have the Radeon Instinct Series Accelerators and the latest M150 accelerators support PCIe4 and have been benchmarked at 6.6TFLOPs for FP64 double-precision floating point operations.
We support the AMD accelerators in some of our Gigabyte and HPe server offerings.

Intel’s FPGA (field programmable gate array) cards are often used to implement algorithms in hardware providing the highest possible performance for these tasks. Sometimes this has applicability in Deep Learning models or in financial systems. They require significant programming effort.
Intel FGPA cards are supported in a few of our HPC systems. Please
contact us for details.

The Alveo U250 is an impressive PCIe3 GPU and is
supported in a limited number of HPC servers including the HPe DL380G10
How Many GPUs?
In most traditional PCIe servers the limit is 4 double width GPUs (or 8
lower powered single width GPUs) supported by specialised power supplies (eg
dual 2000W with 15A power required).
Up to 8 SXM GPU modules are supported in a number of supercomputers we
have available.
The Nvidia DGX-2 system supports up to 16 GPUs in one system making it
the world’s most powerful deep learning server. Nvidia have linked 96 of the
DGX-2 servers into one supercomputer (in the top 100) with 8.8million CUDA and
Tensor cores and 12000 TFLOP performance.


Systems with 2000W or more power supplies are
common and necessary to support the power requirements of the GPUs.
High
performance fans are standard and many vendors offer additional cooling options
such as liquid cooling.
The
systems generally require multiple 15A connections.

Single High-Performance compute can provide more performance than 100 CPU-only nodes.
However, to scale to high-end supercomputers leveraging massive parallel processing it is necessary to interconnect these computers. This is generally achieved with extremely high-speed networking.
Up to 200Gbit/sec networking is available with Mellanox Infiniband and Ethernet. Standards are being finalised for much faster solutions up to 1TBit/sec.
.
.
.
.